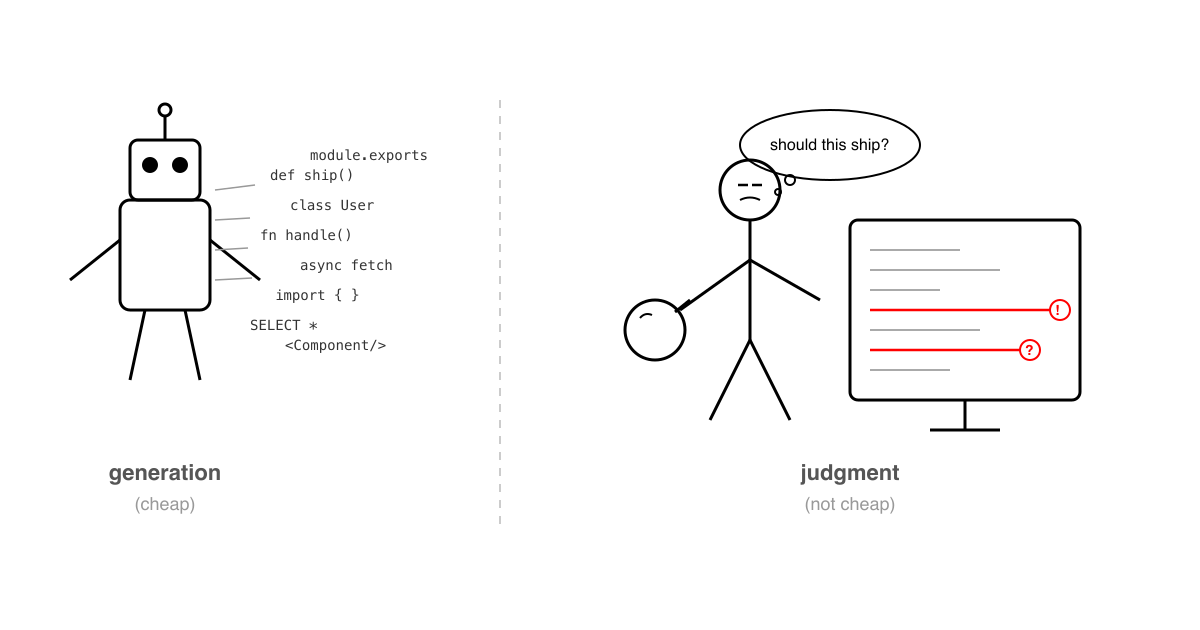
Generation Is Cheap. Judgment Isn't.
With new AI models getting released almost every other day these days (every day?), code generation keeps getting faster.
Git work trees any one?
What used to take a day takes an hour. Sometimes less, if the model is having a good day.
Teams are shipping more code than ever. But someone still has to read it.
The review side never caught up
As generation speeds up, PRs are getting bigger and more frequent. The diffs just keep coming.
Most teams haven’t really adjusted to this. Code review is still treated like the last checkbox before merge. Something you do in between writing your own code.
That framing made sense when writing was the bottleneck.
It isn’t anymore.
These days I easily spend four hours a day reviewing code. Sometimes more.
My updates in the daily standup meeting these days:
- reviewed 2 or 3 PR’s
- made progress on xyz task
What my reviews used to look like
For years my reviews were basically pattern recognition.
I’d catch the things I already knew how to recognize.
The missing null check. The N+1 query I’ve been burned by before. A callback handler where someone forgot the encryption scheme changed upstream.
Stuff like that.
In other words, my reviews were mostly a catalog of my own past mistakes.
If I’d seen it break before, I’d catch it.
If I hadn’t, it probably sailed through.
The harder problems were the ones that sit between systems. The stuff that isn’t obvious in a single file.
A side effect two services downstream. An edge case that only happens when requests arrive in a weird order. A quiet assumption in one module that another module unknowingly depends on.
None of this is about carelessness. It’s just cognitive limits.
Nobody can hold an entire system in their head at once. At least I can’t.
What changed
Recently I started using a Claude Code skill I created myself during the code reviews.
Same series as the earlier posts. Part 1 was PR descriptions. Part 2 was commit messages. This is the review side of that same experiment.
The skill runs over a diff and surfaces a list of potential issues. In case you are wondering, here’s the skill. And here’s a sample review report it generated for a real PR on the Rails codebase.
It surfaces so many things:
Concurrency risks. Boundary conditions. Dependency chains I didn’t trace manually. Assumptions that might break under load.
Just a list.
And honestly most of them don’t matter.
That’s the thing people misunderstand about tools like this. It doesn’t produce a clean report you blindly trust.
Half the warnings are irrelevant in context.
The concurrency issue doesn’t apply because the caller is already serialized. The edge case was intentionally ignored last quarter. The dependency chain is behind a feature flag nobody has turned on yet.
The tool doesn’t know any of that. You do.
So the real workflow becomes filtering.
Out of twenty surfaced issues, maybe four are actually worth commenting on.
Those four depend on things the tool cannot infer. System context, production history, business priorities, the weird bug you spent two days debugging last month and never want to see again.
That’s the review. The judgment step.
And interestingly, I am doing it better now. Not because I am smarter, but because I am choosing from a wider set of possibilities instead of hoping I remembered everything.
The skill that matters now is reading
This part makes a lot of developers uncomfortable.
For most of our careers, writing code was the craft. Clean abstractions. Elegant solutions. The clever one-liner that makes another engineer pause for a second and smile.
That was the thing you got good at.
But writing is exactly the part that is getting automated.
Give a model enough context. The repo structure, a decent system prompt, relevant specs, maybe a plan. The generated code is surprisingly solid.
Not perfect. But good enough that writing is not the bottleneck anymore.
Reading is.
Understanding what a change actually does across a system.
Spotting what is implied but never stated.
Looking at a 15-file PR and knowing which two files actually matter.
That is a skill. And most of us never deliberately practiced it, because historically we did not need to.
Reviews were a side activity.
Now they are not.
If you are a senior engineer in 2026, your highest-leverage skill might not be writing a service from scratch.
It might be reading someone else’s diff and deciding, in twenty minutes, whether it should ship.
The gap is widening
Generation can be automated.
First-pass scanning can be automated.
But deciding whether code should ship. Whether the tradeoff is correct. Whether the edge case matters for this team at this stage. Whether a side effect is acceptable given what you are planning next quarter.
That still requires judgment.
And judgment comes from context the tool does not have.
As generation keeps getting faster, review becomes more important, not less.
The code arrives quicker than ever. Someone still has to decide if it is safe.
I do not think that part gets cheaper.
If anything, it gets harder.
And I suspect the teams that learn how to make their reviewers better, not just their writers faster, are the ones that will actually ship well.
This is Part 3 in my Automating Myself Out of My Job series. Part 1 covered PR descriptions. Part 2 covered commit messages.